重回帰分析
はじめに
以前、1個の説明変数を使って関心ある変数を表現する単回帰モデルについて、基本的な概念と推定方法を説明した。
単回帰分析(1)大雑把な説明 - 統計学入門一歩先へ
単回帰分析(2)モデルの定式化と最小二乗法 - 統計学入門一歩先へ
単回帰分析(3)最尤法による推定 - 統計学入門一歩先へ
しかしながら、単回帰モデルのようなシンプルすぎるモデルでは物足りないことが多くある。今後の予測が目的であればできるだけ多くの情報が必要かもしれないし、説明変数の影響の大きさを評価したい場合にはいくつかの変数について「調整」をしなければ正しい結論が得られないこともある。そこで、複数の説明変数を使って関心のある変数を説明するモデルを構成したい。このようなモデルを用いた分析を「重回帰分析(Multiple regression)」という。
今回は重回帰分析の数学モデルについて簡単に触れ、例題を見ながら解釈のしかたを確認していこうと思う。
重回帰分析モデル
単回帰分析では、目的変数を1つの説明変数
を使って
重回帰分析では、
モデルのパラメータ(未確定の値)
まず、説明変数
さて、サンプルサイズをNとすると、目的変数と説明変数ベクトルはそれぞれ
結果の解釈
では、このようにして推定されたモデルの結果をどのように解釈すればよいだろうか?ここでは、以前具体例として使った「中間テストと期末テストの得点の関係」をアレンジした例を使って考えてみたい。
今回は中間テストの得点(横軸)と期末テストの得点(縦軸)の間に以下のような関係がみられているとする。
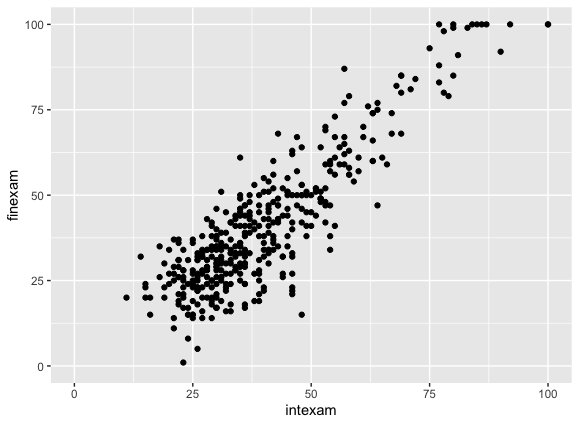
このデータに対して、期末テストの得点を目的変数、中間テストの得点を説明変数とする単回帰モデルを用いると、次のような直線が当てはめられる。
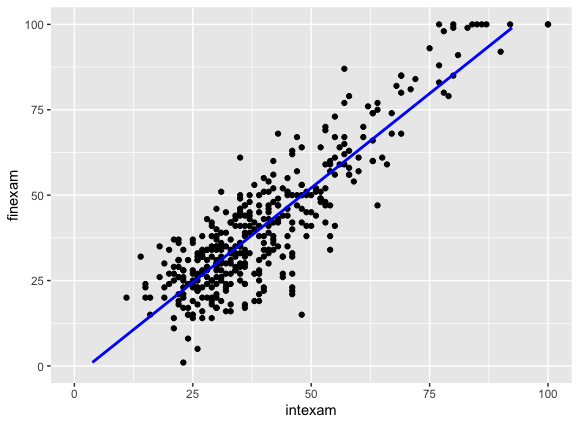
また、以下のアウトプットから、例えば中間テストの得点が10点上がるごとに期末テストの得点はおよそ11点上がる、という強い関係性が示唆される(「Coefficients:」の「intexam」の行のEstimateの値「1.10574」が、中間テストの得点が1点上がった時に期末テストの得点が何点上がっているかを表す)。
Call:
lm(formula = finexam ~ intexam, data = df)
Residuals:
Min 1Q Median 3Q Max
-34.903 -6.319 0.155 6.811 27.146
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.17316 1.29697 -2.447 0.0149 *
intexam 1.10574 0.03018 36.641 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 9.51 on 398 degrees of freedom
Multiple R-squared: 0.7713, Adjusted R-squared: 0.7708
F-statistic: 1343 on 1 and 398 DF, p-value: < 2.2e-16ということは、(単回帰の記事で登場した)この学生の言うように、中間テストの得点で期末テストの得点が決まってしまうことになり、勉強しても無駄なのだろうか?
ここで、「前期での1日あたり自主学習時間」というデータをとっていたとしよう。前期の自主学習時間と今期の中間テストの得点との相関をみてみると、次のようにかなり強い相関があったとする(intexamは中間テストの得点、studytimeは前期の自主学習時間):
cor(df$intexam, df$studytime) [1] 0.9107677
さらに、期末テストの得点との相関も次のようだったとする:
> cor(df$finexam, df$studytime) [1] 0.9234282
素直に考えると、前期に自主学習を長い時間やっていた学生は今期の中間テストも、期末テストもよい成績になるという因果関係がありそうである(あくまで説明のための例ということで、かなり乱暴な議論であることをご了承いただきたい)。
整理すると、中間テストの得点と期末テストの得点の他に、第3の要因「前期の学習時間」があり、これはどちらの得点にも影響を与えていることがわかっている状況である。

このような時、「前期の学習時間」による交絡が起こり、これを抜きに考えると中間テストの得点と期末テストの得点の間の関係性が正しく評価できない可能性がある。そこで、「前期の学習時間」を説明変数に追加した重回帰分析を行うことで、「もしも前期の学習時間が同じだった時、中間テストの得点と期末テストの得点にはどの程度の関係があるか」を推定することができるようになる(前期の学習時間を「調整する」という言い方をする)。
実際にやってみると、以下のようになる。
Call:
lm(formula = finexam ~ intexam + studytime, data = df)
Residuals:
Min 1Q Median 3Q Max
-27.9823 -4.4413 0.6285 4.6273 23.9977
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 15.93312 1.56706 10.168 < 2e-16 ***
intexam 0.27491 0.05708 4.816 2.09e-06 ***
studytime 0.24215 0.01515 15.981 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 7.428 on 397 degrees of freedom
Multiple R-squared: 0.8608, Adjusted R-squared: 0.8601
F-statistic: 1228 on 2 and 397 DF, p-value: < 2.2e-16「intexam」の行のEstimateの値は0.27491となり、前期の学習時間(studytime)を説明変数に入れなかった場合の1.10574とはかなり異なる結果になった。これは、「前期の学習時間が同じ人どうしで考えると」、中間テストの得点が10点上がっても、期末テストの得点は3点も上がらないことを意味する。つまり中間テストと期末テストの間には、単回帰分析でみられたような直接的な関係はあまりないということになる。
一方、「中間テストの得点が同じ人どうしで考えると」、前期の学習時間が1日あたり60分長かった場合、期末テストでは点ほど良い成績になっていたと推測できる・・・と言いたいところだが、
・前期の学習時間→中間テスト→期末テスト
・前期の学習時間→期末テスト
という2つの因果の経路がある場合、中間に位置する変数(中間テスト)をモデルに含めると前期の学習時間の効果は正しく推定できないことが知られている。このあたりの話は本題ではないのでこれ以上は述べないことにするが、もし前期の学習時間が期末テストに与える影響を調べたいのであれば、前期の学習時間だけを説明変数にすればよい。
このように、原因と思われる変数(ここでは中間テストの得点)と結果と思われる変数(ここでは期末テストの得点)の両方に影響を与えるような変数がある(交絡が存在する)場合には、重回帰分析を用いることでその影響を取り除いて評価することができる。ひとまず今回の例では、中間テストの得点と期末テストの得点との間には見かけだけの関連が生じていたに過ぎず、習慣的な勉強が影響していそうだとは言えそうである。
