線形モデルにおけるダミー変数
はじめに
前回紹介した「重回帰分析」は、統計モデルによって表現したい変数*1が正規分布に従うものと仮定した上で*2、その平均(期待値)を複数の要因(説明変数)によって説明する方法である。
mstour.hatenablog.com
前回見たように、重回帰分析モデルは、目的変数の平均を様々な要因の足し合わせで表現している。このようにモデルの構造が線形になっているような統計モデルは「線形モデル(Linear model)」と呼ばれることが多い。なお重回帰分析モデルは正規分布の仮定にちなみ「正規線形モデル(Normal linear model)」と呼ぶこともできる。
ところで、線形モデルは、目的変数の従う確率分布を正規分布に限定する必要はなく、「一般化線形モデル(Generalized linear model)」という形でさらなる拡張がなされている(例えばロジスティック回帰分析は、目的変数の分布を「ベルヌーイ分布」としたモデルである)。また、同じ個体から繰り返しデータを測定するような場合など、目的変数どうしに相関が生じるような状況に有効である「混合モデル(Mixed model)」も線形モデルの拡張と言える。
今後、こういった線形モデルの発展形を色々と紹介していきたいのだが、ここで「ダミー変数(Dummy variable)」なる概念について述べておきたい。
ダミー変数を用いた表現
ダミー変数が必要となるのは、線形モデルの説明変数としてカテゴリー型(離散型)変数が含まれるような場合である。
例えば、期末テストの点数を目的変数、その学期に参加した補習の種類(「放課後のみ」、「始業前+放課後」、「なし」の3カテゴリー)を説明変数とした線形モデルを考えてみよう。
学生の期末テストの点数を
とすると、
は次のように表現できる:

さて、N人分の期末テストの点数に関するモデルをベクトルと行列を用いて表すことにする。「放課後のみ」「始業前+放課後」「なし」のグループの人数をそれぞれ
この時、デザイン行列
各列を説明変数と考えれば、この線形モデルには各学生がどのグループに所属するかを示す説明変数が3個あると考えることができる*3。このように定められた変数をダミー変数と呼ぶ。
ところが、最小二乗法によるパラメータベクトルの推定量は前回の記事で紹介した通り
この問題を解決する方法の一つとして、カテゴリー型説明変数(ここの例では補習の種類)の「基準カテゴリー(例えば補習なし)」の平均を

重回帰モデルと同様の表現
モデル(1)は、一般的な重回帰モデルの形式で書くこともできる。
ただし、ここでも先ほど述べたようにパラメータベクトルの推定計算ができない問題が生じるので、基準カテゴリーを決める必要がある。
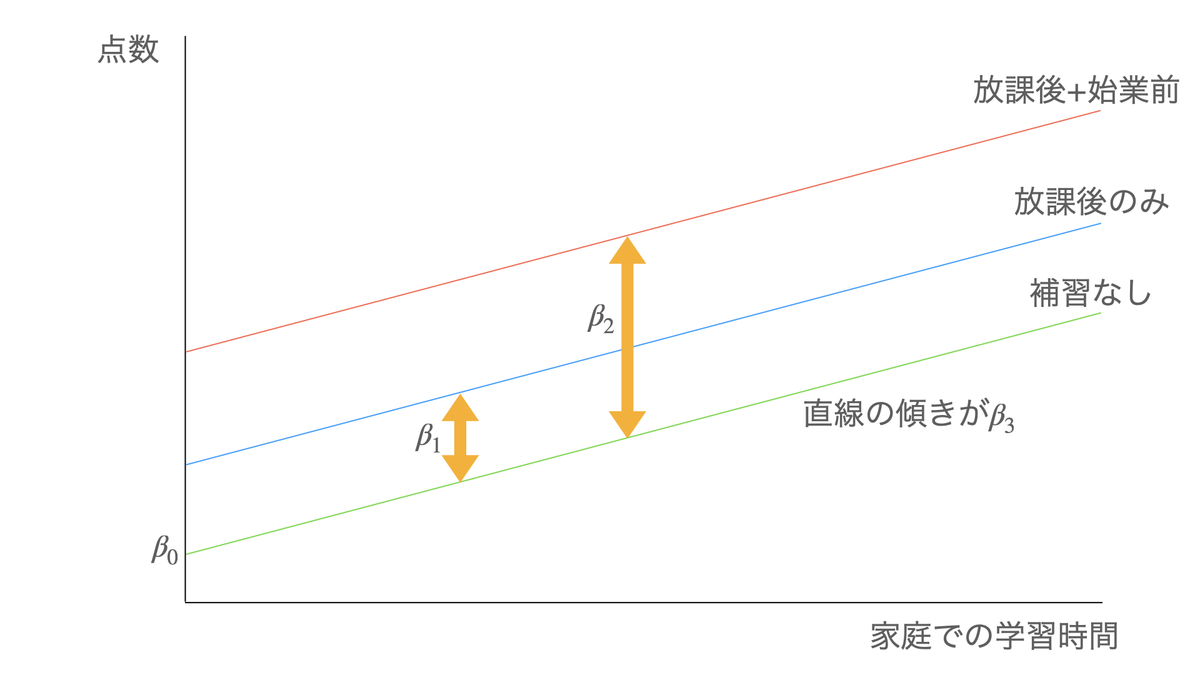
基準カテゴリーを補習なしのグループとすると、モデルは以下のようにすればよい。

連続型とカテゴリー型の説明変数を混在させることも可能で、例えば上記モデル(3)に家庭での学習時間を説明変数として追加すると
なおダミー変数を使用する場合、データの形は例えば以下の図のようになる。

またダミー変数を説明変数に含めた重回帰分析を行うと、例えば次のような結果が得られる。各ダミー変数の係数の推定値が、基準カテゴリー(ここでは補習なし)と各カテゴリーとの差である。
