傾向スコアを用いたOverlap weighting
はじめに
傾向スコアを用いた解析の代表的な方法の一つとして、個人ごとの傾向スコアの推定値*1による重み付け解析があります。
重み付け解析としては、傾向スコア推定値の逆数で重み付けを行う「逆確率重み付け法(Inverse probability of treatment weighting; IPTW)」が有名で広く利用されていますが、この方法は傾向スコアの推定値に0または1に近いものがあった場合(つまり、重みが非常に大きくなる場合)に、推定のバラツキが大きくなってしまうという難点があります。そのため、例えば極端な重みの値を持つ個人を解析から除外する「トリミング(Trimming)」などの方策がこれまでにも提案されてきました。
一方で最近では、新しいタイプの重み付け手法である「Overlap weighting」が提案されています。この方法については、Liらの2018年の論文(参考資料[1])をはじめいくつか詳しく論じた文献があります。
Overlap weightingには、
- 重みが必ず0から1の間の値になる
- 傾向スコアによる重み付け解析の中では、最も推定精度が高い*2
- ロジスティック回帰で傾向スコアを推定した場合、背景因子の平均が処置グループ間で完全に一致する(平均の差がゼロになる)
といった理論的に優れた特徴があり、また
- いずれの処置を受ける可能性も同程度あるような集団に対する処置効果を推定する
という実際的な特徴も持っています。
今回は、Overlap weightingの概要と、Rでの解析例を紹介したいと思います。
Overlap weightingとは
傾向スコアによるIPTW
一般に重み付け解析では、各個人のデータに、対応する重みを掛け算したものをその個人のデータとみなして解析を行う形になります。
個人の重みを
とすると、例えば変数
の重み付け平均は
により計算されます。なお分母は重みの合計です。
重みは各個人のデータがそれぞれ何人分の価値があるのかを表している、と考えると理解しやすいと思います。
処置群と対照群の平均の差を考える場合には、次のように表現することが多くあります。
ここでは個人
が処置群に所属している場合1を、対照群に所属している場合0をとる変数です。
したがっては処置群の人数、
は対照群の人数を意味しており、上記は処置群の重み付け平均と対照群の重み付け平均の差を表していることになります。
さて、傾向スコアによる重み付け解析のうち、IPTWは「逆確率重み付け法」の名前の通り、「割り当てられた処置を受ける確率の逆数で重み付けする」方法でした。
つまり、IPTWで使用する重みは推定された傾向スコア(=処置を受ける確率。
は処置を受けない確率)の逆数で、処置群の場合
、対照群の場合
となります。
上記の定義をよく見るとわかるように、傾向スコアが0に近い(=本来なら処置を受けなさそうな)個人が処置群に所属する場合・あるいは1に近い(=本来なら処置を受けそうな)個人が対照群に所属する場合には、重みが非常に大きな値になってしまいます。
これらの状況では、処置効果の推定にバイアスが入ったり、推定のバラツキ(分散)が大きくなるなどの問題が生じることが知られています。
Overlap weighting
一方で、近年提案されたのがOverlap weightingと呼ばれる重み付け解析方法です。
Overlap weightingに用いる重み(Overlap weightと呼びます)は、自分が属していない群に属する確率(つまり、処置群に所属する個人であれば、対照群に属する確率)として定義されます。この重みは推定した傾向スコアで表すことができ、処置群の場合、対照群の場合
となります。
Overlap weightingには、傾向スコアの値が0.5に近い個人が処置効果の推定に最も影響を与える一方、0あるいは1に近づくにつれて影響度が小さくなるという特徴があります。
具体的に、単純なケースで考えてみましょう。
処置群、対照群それぞれに150人ずつがいるものとし、下記の表の「傾向スコア」の列には各個人のもつ傾向スコアの値、「人数(%)」の列はその傾向スコアの値をもつ個人の人数および構成割合(%)を示しています。また、「IPTW後の人数(%)」「OW後の人数(%)」はそれぞれIPTW、Overlap weighting(OW)を行った後の(仮想的な)人数および構成割合です。
<処置群>
| 傾向スコア | 人数(%) | IPTW後の人数(%) | OW後の人数(%) |
|---|---|---|---|
| 0.5 | 50(33.3%) | 2 |
0.5 |
| 0.2 | 20(13.3%) | 5 |
0.8 |
| 0.8 | 80(53.3%) | 1.25 |
0.2 |
<対照群>
| 傾向スコア | 人数 | IPTW後の人数(%) | OW後の人数(%) |
|---|---|---|---|
| 0.5 | 50(33.3%) | 2 |
0.5 |
| 0.2 | 80(53.3%) | 1.25 |
0.2 |
| 0.8 | 20(13.3%) | 5 |
0.8 |
この例では、IPTWを行うと、どの傾向スコアの値をもつ個人も各群における構成割合は33.3%となり、処置効果の推定に等しく影響することになります。
一方でOWでは傾向スコアの値が0.5の個人の構成割合が半数近くになっており、逆に傾向スコアの値が0あるいは1に近づくほど構成割合が小さくなっているのがわかります。したがって、OWでは、傾向スコアが0.5に近い個人ほど処置効果の推定に強く影響することになります。
(上記の数値例を再現するRコード例です。)
library(tidyverse)
library(WeightIt)
x <- c(rep("A", 50), rep("B", 20), rep("C", 80), rep("A", 50), rep("B", 80), rep("C", 20))
trt <- c(rep("T", 150), rep("C", 150))
toy_df <- tibble(covariate = x, treat = trt)
toy_ps <- weightit(trt ~ covariate, data = toy_df, method = "ps", estimand = "ATE")
toy_df_weight <- toy_df %>%
mutate(ps = toy_ps$ps,
iptw_wgt = case_when(treat == "T" ~ 1/ps, treat == "C" ~ 1/(1-ps)),
ovlp_wgt = case_when(treat == "T" ~ 1-ps, treat == "C" ~ ps))
toy_df_weight %>% group_by(treat, ps) %>%
summarise(iptw_size = sum(iptw_wgt), ovlp_size = sum(ovlp_wgt))
このようにOverlap weightingは傾向スコアが0.5に近い(背景因子が処置群間でオーバーラップするような)集団に重点を置くため、重み付け解析によって得られる処置効果の推定値は処置群・対照群をあわせた全体集団に対するもの(平均処置効果(Average treatment effect; ATE))ではなくなります。
Overlap weightingを用いて推定した処置効果のことは、文献によってはAverage treatment effect for the overlap population(ATO)と呼ばれています。
ATOは傾向スコアが0.5に近い個人に大きな重みが置かれているため、異なる処置Aと処置Bのどちらを受ける可能性も同じくらいあるような集団での効果を見ているものと解釈できます。
例えば、軽症の患者には治療Aが、重症の患者には治療Bが標準治療とされているが、中程度の症状の患者にはどちらの治療をすればよいか分かっていないため両方の治療が選択されうる、という状況を考えてみます。
このような場合、重症度を用いて治療Aに対する傾向スコアを推定すると*3、軽症患者は1に近い値、中程度の患者は0.5に近い値、重症患者は0に近い値が得られるでしょう。そこでOverlap weightingを行うと、中程度の患者を中心とした集団での処置効果(治療Aと治療Bとの差)を推定できるはずです。

臨床研究の文脈における解説として、例えばThomasらのJAMAの記事(参考文献[2])が参考になります。
Overlap weightingは元々は統計の理論的な面から研究がなされており、様々な重み付け解析の中で処置効果の推定量の漸近分散が最小になることが示されています。
またロジスティック回帰で傾向スコアを推定した場合に、Overlap weighting後の背景因子の平均がグループ間で一致するという性質もあります(後述する例もご覧ください)。
純粋に統計的な観点からよい性質をもつだけでなく、重み付け解析で推定した処置効果を明快に解釈できるため、理論・応用の両面から今後利用が広がっていくものと思われます。
Rによる解析例
Overlap weightingは、前回の記事で紹介したRのPSweightパッケージで行うことができます。
mstour.hatenablog.com
前回と同じく、twangパッケージに付属しているデータセットである"lindner"を用いて解析例を紹介していきます。
lindnerデータセットの説明については、前回の記事やtwangパッケージの解説などをご参照ください。
まずはPSweightとtwangを読み込み、lindnerデータセットも準備します。
library(PSweight)
library(twang)
data("lindner", package = "twang")PSweightパッケージを用いた重み付け解析の流れは、前回紹介したものと同様です。
まず傾向スコアのモデル式を定義します。
# PSのモデル式 psmodel_ovlp <- abcix ~ stent + height + female + diabetic + acutemi + ejecfrac + ves1proc
ここで、重み付けをした場合の背景因子のバランスがどうなるかを確認しておきます。
最初にSumStat関数でweight = "overlap"と指定することでoverlap weightの計算を行い、続いてplot関数でtype = "balance"を指定することで、Overlap weightingを行った際の背景因子の標準化差(Standardized mean difference)を確認できます。
# weighting後のバランス bal_ovlp <- SumStat(ps.formula = psmodel_ovlp, data = lindner, weight = "overlap") plot(bal_ovlp, type = "balance")
IPTWを行った場合との違いを見てみましょう。上の図の赤丸がIPTW、下の図の赤丸がOverlap weightingでの標準化差です。


このデータにおいては、IPTWを行うことで背景因子の標準化差はすべて0.1未満になり、治療グループ間でおおむねバランスがとれているといえます。
ところが、Overlap weightingを行った場合には、背景因子の標準化差は完全に0になっています。これは理論的に示されているOverlap weightingの一つの特徴であり、交絡によるバイアスを取り除いたり推定精度を上げるために有効であると考えられます。
一方で前述の通り、IPTWとOverlap weightingとでは、一般に処置効果の推定の対象となる集団が異なってくることに注意が必要です。
調整に用いた背景因子について、Overlap weightingとIPTWそれぞれによる重み付け後の要約統計量を見てみると、今回のデータでも若干の差異があることがわかるかと思います。例えばacutemi(急性心筋梗塞)の割合はOverlap weightingではIPTWの場合の半分ほどになっています。
なおPSweightなどのパッケージ単体では簡単に背景集計ができないようでしたので、今回は重みを算出し直した上で、gtsummaryパッケージの"tbl_svysummary"という重み付け集計の関数を使用して計算しました(参考資料[6])。
# 傾向スコアの算出
psmodel_man <- glm(abcix ~ stent + height + female + diabetic + acutemi + ejecfrac + ves1proc,
data = lindner, family = binomial)
ps_man <- psmodel_man$fitted.values
# overlap weightと逆確率重みをデータセットに格納
wgt_man <- lindner %>%
mutate(ps = ps_man,
ovlp_wgt = case_when(abcix == 1 ~ (1-ps_man), abcix == 0 ~ ps_man),
iptw_wgt = case_when(abcix == 1 ~ 1/ps_man, abcix == 0 ~ 1/(1-ps_man))
)
# surveyパッケージで重み付けした後、gtsummaryパッケージで集計
library(gtsummary)
library(survey)
## Overlap weighting
tbl_ovlp <- svydesign(~1, data = wgt_man, weights = wgt_man$ovlp_wgt) %>%
tbl_svysummary(include = c(stent, height, female, diabetic, acutemi, ejecfrac, ves1proc),
type = list(stent ~ "dichotomous",
height ~ "continuous",
female ~ "dichotomous",
diabetic ~ "dichotomous",
acutemi ~ "dichotomous",
ejecfrac ~ "continuous",
ves1proc ~ "continuous"),
by = abcix,
statistic = list(all_continuous() ~ "{mean}({sd})"),
digits = list(all_continuous() ~ c(1, 2), all_categorical() ~ c(0, 1))) %>%
modify_header(label = "**After Overlap weighting**")
tbl_ovlp
## IPTW
tbl_iptw <- svydesign(~1, data = wgt_man, weights = wgt_man$iptw_wgt) %>%
tbl_svysummary(include = c(stent, height, female, diabetic, acutemi, ejecfrac, ves1proc),
type = list(stent ~ "dichotomous",
height ~ "continuous",
female ~ "dichotomous",
diabetic ~ "dichotomous",
acutemi ~ "dichotomous",
ejecfrac ~ "continuous",
ves1proc ~ "continuous"),
by = abcix,
statistic = list(all_continuous() ~ "{mean}({sd})"),
digits = list(all_continuous() ~ c(1, 2), all_categorical() ~ c(0, 1))) %>%
modify_header(label = "**After IPTW**")
tbl_iptw

では、Overlap weightingにより処置効果を推定します。
推定計算は"PSweight"関数で行い、結果を"summary"関数で表示します。二値アウトカムの場合、type = "DIF"を指定すると割合の差(リスク差)が出力されます。
割合の比(リスク比)やオッズ比を算出したい場合はそれぞれtype = "RR"、type = "OR"と指定します。
est_ovlp <- PSweight(ps.formula = psmodel_ovlp, yname = "sixMonthSurvive", data = lindner,
weight = "overlap")
summary(est_ovlp, type = "DIF")以下の出力のように、6ヶ月後の生存割合の差は4.01%(95%信頼区間は1.12 - 6.78%)という結果でした。
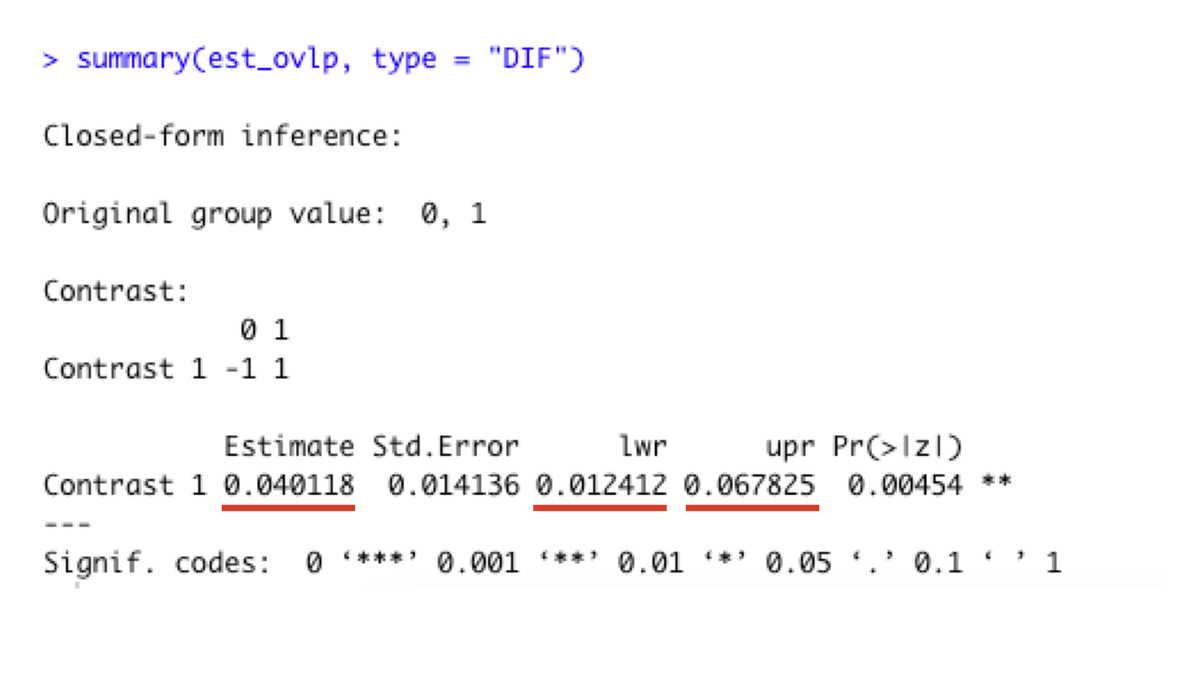
なおIPTWによる推定値は6.61%(95%信頼区間は1.21 - 12.0%)になりました。
あくまで例示用の模擬データではありますが、
- 推定対象となる集団が異なるために、処置効果(生存割合の差)はOverlap weightingとIPTWとで異なる結果になった
- Overlap weightingのほうがIPTWよりも背景因子を強力にバランスさせてくれた結果、バラツキが小さくなり、信頼区間の幅が狭くなった
といえるのではないかと思います。
まとめ
今回は傾向スコアによる重み付け法のひとつであるOverlap weightingを紹介しました。
最もポピュラーな重み付け法であるIPTWは、集団全体における処置効果を推定することのできる強力な方法ですが、傾向スコアに極端な値が存在する場合には推定にバイアスが入る危険があるのが難点です。
Overlap weightingでは、重みは必ず0〜1の間の値をとるため、IPTWのように極端な重みに引きずられることがありません。また今回詳しくは述べませんでしたが、背景因子のバランスや推定精度の面で優れた性質を持っています。
うまく使いこなすことができればとても魅力的な方法だと思います。
Overlap weightingの方法論に関する参考文献はこちら。
[1] Li, F., Morgan, K. L., & Zaslavsky, A. M. (2018). Balancing covariates via propensity score weighting. Journal of the American Statistical Association, 113(521), 390-400.
[2] Thomas, L. E., Li, F., & Pencina, M. J. (2020). Overlap weighting: a propensity score method that mimics attributes of a randomized clinical trial. Jama, 323(23), 2417-2418.
[3] Li, F., Thomas, L. E., & Li, F. (2019). Addressing extreme propensity scores via the overlap weights. American journal of epidemiology, 188(1), 250-257.
Rでの実行に関する参考文献はこちら。
[4] Propensity Score Weighting in R: A Vignette.
https://cran.r-project.org/web/packages/PSweight/vignettes/vignette.pdf
[5] Ridgeway, G., McCaffrey, D., Morral, A., Cefalu, M., Burgette, L., Pane, J., & Griffin, B. A. (2021). Toolkit for Weighting and Analysis of Nonequivalent Groups: A guide to the twang package. vignette, July, 26.
[6] Create a table of summary statistics from a survey object — tbl_svysummary • gtsummary